
バックテストをしていて最大ドローダウンを計算したかったので調べてみました。
環境
- Python 3.5.2
- pandas 0.22.0
- NumPy 1.14.3
最大ドローダウン
最大資産(累積利益)からの下落率のこと。システムトレードなどでは、最大ドローダウン(下落率)をどれだけに設定するかがリスク管理の観点から重要な要素の一つとなる。
Stack Overflow
検索したら Stack Overflow に同じ質問をしていた人がいました。
Just find out where running maximum minus current value is largest:
n = 1000 xs = np.random.randn(n).cumsum() i = np.argmax(np.maximum.accumulate(xs) - xs) # end of the period j = np.argmax(xs[:i]) # start of period plt.plot(xs) plt.plot([i, j], [xs[i], xs[j]], 'o', color='Red', markersize=10)numpy - Start, End and Duration of Maximum Drawdown in Python - Stack Overflow
計算しているのは 3 行だけみたいです。 これだけで計算できてしまうのですね。
関数
NumPy はあまり使ったことがないのでそれぞれが何をしているのかよくわかりませんでした。 なので、それぞれの関数を調べてみました。
randn
Return a sample (or samples) from the “standard normal” distribution.
名前からしてもランダムな値を返してくれそうです。 引数に指定した数だけ配列を作ってランダムな値を返してくれるようです。
np.random.random(3)
結果です。
array([0.23766355, 0.23769627, 0.38886935])
randn はテストデータを作るために使っているようなので、最大ドローダウンの計算とはあまり関係ないみたいでした。
cumsum
Return the cumulative sum of the elements along a given axis.
合計しながら累積してくれる関数のようです。
l = [-20, 7675, 965, -8790, -3463, 18715, 2526, -5699, -6384, 4865]
ndarray1 = np.array(l).cumsum()
ndarray1
結果です。
array([ -20, 7655, 8620, -170, -3633, 15082, 17608, 11909, 5525, 10390])
こういう関数は JavaScript にはない気がします。
const cumsum = (a) => (
a.reduce((pv, cv) => {
pv.push((pv.length > 0 ? pv[pv.length - 1] : 0) + cv)
return pv
}, [])
)
console.log(cumsum([1, 2, 3, 4, 5]))
// [ 1, 3, 6, 10, 15 ]
関係ないですけれども、 JavaScript で cumsum を実装してみました。
アキュムレーターの pv に push しているのがなんか気持ち悪いです。
話を戻して。 cumsum した結果のグラフを載せておきます。
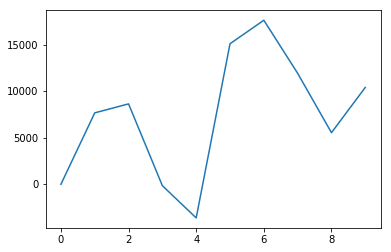
accumulate
Accumulate the result of applying the operator to all elements.
numpy.ufunc.accumulate は、すべての要素に ufunc を適用しながら累積してくれるようです。
ちょっと、 numpy.cumsum の “cumulative” と、 numpy.ufunc.accumulate の “Accumulate” の違いが気になったので調べてみました。
なんで “accumulate” の方は “ac-” がついているのかな?
ac‐
音節ac‐ 発音記号・読み方/æk/
【接頭辞】
(c,q,k の前にくるときの) ad‐ の異形.
ad‐
音節ad‐ 発音記号・読み方/æd, əd/
【接頭辞】
「…へ」「…に」 《★「移動」「方向」「変化」「完成」「近似」「固着」「付加」「増加」「開始」の意,また単なる強意》.
“ac-” は “ad-” の異形のようです。 「変化」とか「増加」とかの意味がありそうかな。
次は、なんで “cumulative” の方は “-tive” で、 “Accumulate” の方は “-late” なのかな?
cumulate と accumulate はどう違いますか?
In both of those sentences “accumulate” is correct. “Cumulate” might also be correct but it's not really a commonly-used word. I don't think a native English speaker would ever use cumulate in those contexts Related words like cumulative are more common but I never hear people use the word cumulate in everyday speech.
What is the difference between “accumulative” and “cumulative”?
I'm having a hard time understanding the real distinction between accumulative and cumulative.
英語を母国語とする人でも単語の意味を質問するんだ?と思いましたが、日本人も日本語の単語を質問しているので、当然と言えば当然か、と思いました。
cumulative と Accumulate ってどちらも “累積” のような意味があるみたいです。 細かい違いはわからないですけれども。 形容詞的に使う場合は cumulative を使うことが多いのかな。 動詞的に使う場合は Accumulate を使うことが多いのかな。 上の引用の回答から察するとそう感じました。
話を戻して。
A universal function (or ufunc for short) is a function that operates on ndarrays in an element-by-element fashion, supporting array broadcasting, type casting, and several other standard features. That is, a ufunc is a “vectorized” wrapper for a function
ufunc 自体の説明は読んでもあまりよくわかりませんでした。
numpy.ufunc.accumulate で言うと、 accumulate (累積)しながら Universal (汎用)な関数 (ufunc) を適用してくれるものだと認識しました。
Examples
1-D array examples:
>>> np.add.accumulate([2, 3, 5]) array([ 2, 5, 10]) >>> np.multiply.accumulate([2, 3, 5]) array([ 2, 6, 30])
accumulate の Examples を見ると、 add という ufunc で加算しながら累積できて、 multiply という ufunc で乗算しながら累積できることがわかりました。
np.add.accumulate は numpy.cumsum と同じ意味ですね。
ndarray2 = np.maximum.accumulate(ndarray1)
ndarray2
結果です。
array([ -20, 7655, 8620, 8620, 8620, 15082, 17608, 17608, 17608, 17608])
グラフを載せておきます。
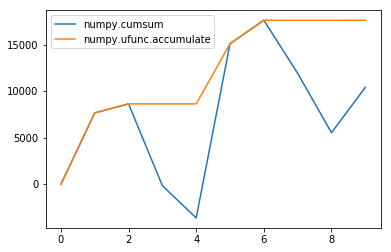
このグラフの 2 つのラインの差が一番大きいところが最大ドローダウンになるみたいです。 パッと見た感じではインデックスが 4 のところぽいですけれども、どうかな。
Basic Operations
Arithmetic operators on arrays apply elementwise. A new array is created and filled with the result.
NumPy の ndarray 同士を算術演算子で計算することができるみたいです。 要素ごとの計算を繰り返しの処理なしに 1 行で記述できてしまうみたいです。 NumPy 便利です。
np.maximum.accumulate した結果から cumsum した結果を減算します。
ndarray3 = ndarray2 - ndarray1
ndarray3
結果です。
array([ 0, 0, 0, 8790, 12253, 0, 0, 5699, 12083, 7218])
やっぱりインデックス 4 のところが一番大きいみたいでした。
max
Stack Overflow の質問では最大ドローダウンの値を求めてはいないみたいでしたが、今回は値を求めたかったので、 numpy.amax 関数を使ってみました。
np.amax(ndarray3)
結果です。
12253
インデックス 4 のところの 12253 の値を求めることができました。
なので、最大ドローダウンは 12,253 ということになります。 最大ドローダウンは口座残高の 20% 程度におさまるといいなと思っているのですけれども、そんな売買ルールができるかな。
NumPy の ndarray を使って最大ドローダウンを計算する関数
最大ドローダウンを計算する関数にしてみました。
def mdd(a):
a1 = a.cumsum()
a2 = np.maximum.accumulate(a1)
a3 = a2 - a1
return a3.max()
mdd(np.array([-20, 7675, 965, -8790, -3463, 18715, 2526, -5699, -6384, 4865]))
結果です。
12253
pandas の Series を使って最大ドローダウンを計算する関数
pandas でもできそうでしたので、同じように最大ドローダウンを計算する関数にしてみました。
def mdd(s):
s1 = s.cumsum()
s2 = s1.cummax()
s3 = s2 - s1
return s3.max()
mdd(pd.Series([-20, 7675, 965, -8790, -3463, 18715, 2526, -5699, -6384, 4865]))
cumsum と cummax と max の関数を使ってみました。
結果です。
12253
Gist のソース
調べたことを Jupyter Notebook にして Gist にアップしました。
終わり
こういうのを調べてみて NumPy や pandas の便利なところが少しずつ分かってきた気がします。
27 Sep 2018 追記
最大ドローダウン率も計算してみました。
NumPy
def mddr(a):
a1 = a.cumsum()
a2 = np.maximum.accumulate(a1)
a3 = a2 - a1
i = np.argmax(a3)
r = (a2[i] - a1[i]) / a2[i]
return r
mddr(np.array([-20, 7675, 965, -8790, -3463, 18715, 2526, -5699, -6384, 4865]))
numpy.argmax を使いました。
結果です。
1.421461716937355
pandas
def mddr(s):
s1 = s.cumsum()
s2 = s1.cummax()
s3 = s2 - s1
i = s3.idxmax()
r = (s2[i] - s1[i]) / s2[i]
return r
mddr(pd.Series([-20, 7675, 965, -8790, -3463, 18715, 2526, -5699, -6384, 4865]))
pandas.Series.idxmax を使いました。
結果です。
1.421461716937355